 Setup a round-robin distribution of jobs across workstations. This blog is about a Dynamic Scheduling scenario in Workload Automation. It aims to help you get the most out of Dynamic Scheduling and optimize the execution of jobs in your scheduling environment. Sometimes, jobs are identified as more critical than others since they can have a huge impact on the performances of the workstation where they run. You might select specific workstations to run these jobs, with the requirement that 2 of these jobs cannot run simultaneously on the same workstation. Let’s see how you can realize the optimal distribution of critical jobs across these workstations. Once the workstations have been identified, it is necessary to create a set of logical resources with the same type. Each logical resource must be linked to one of the selected workstations, must have its own name and the same type of resources as the other. 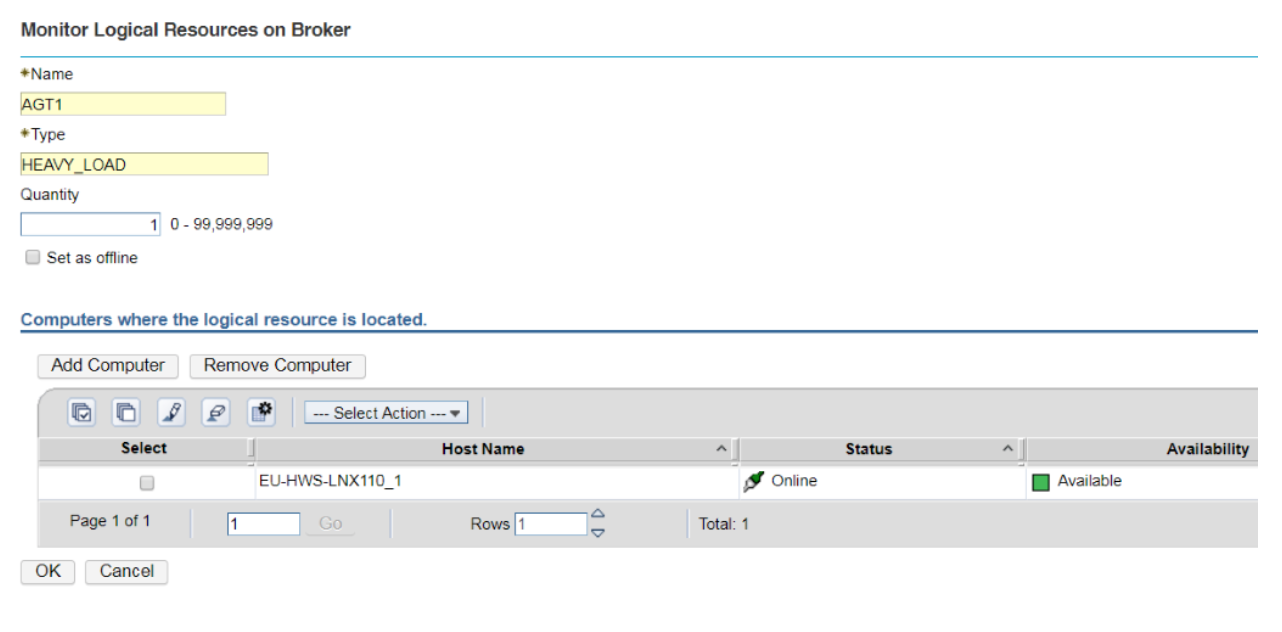 In this example, for the workstation EU-HWS-LNX110_1 the logical resource AGT1, having type HEAVY_LOAD, has been created. 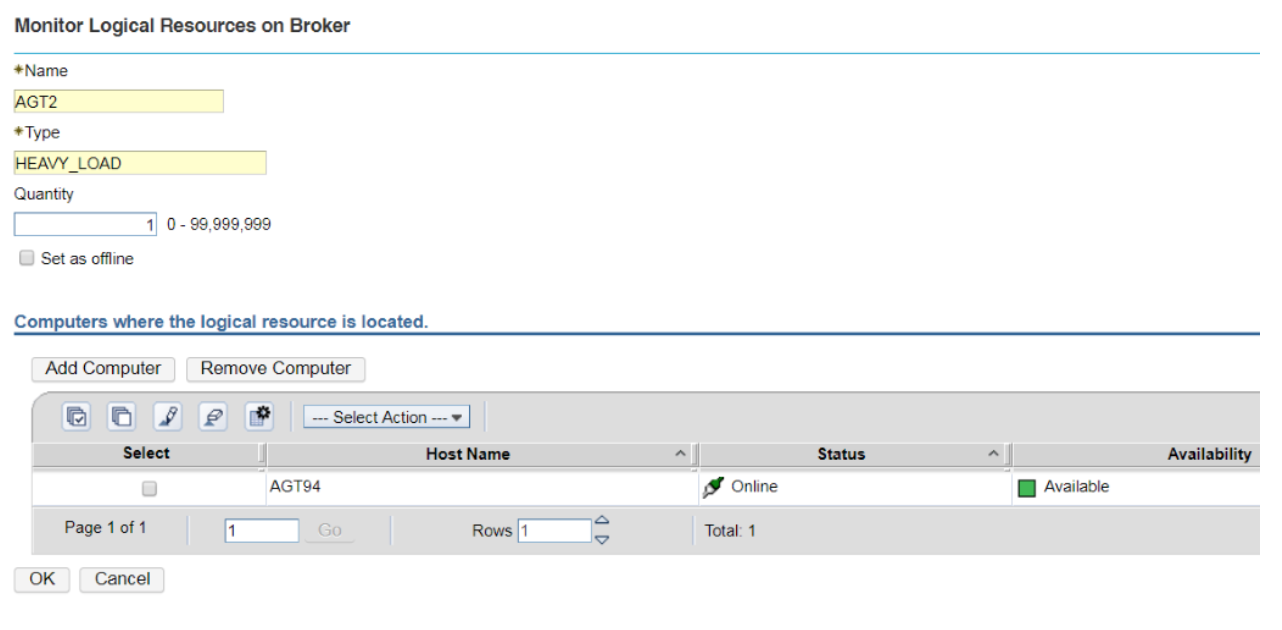 Also, the logical resource AGT2 is created. It has the same type, HEAVY_LOAD. Both the resources have quantity 1 in order to avoid that 2 of the jobs with high impact run together on the same agent. Note that this second resource is related to another workstation, AGT94 (the second workstation that has been selected to host the critical jobs). Then, it is necessary to create a dynamic pool that will be reserved to these specific jobs. In this case the name of the pool is CPU_POOL. 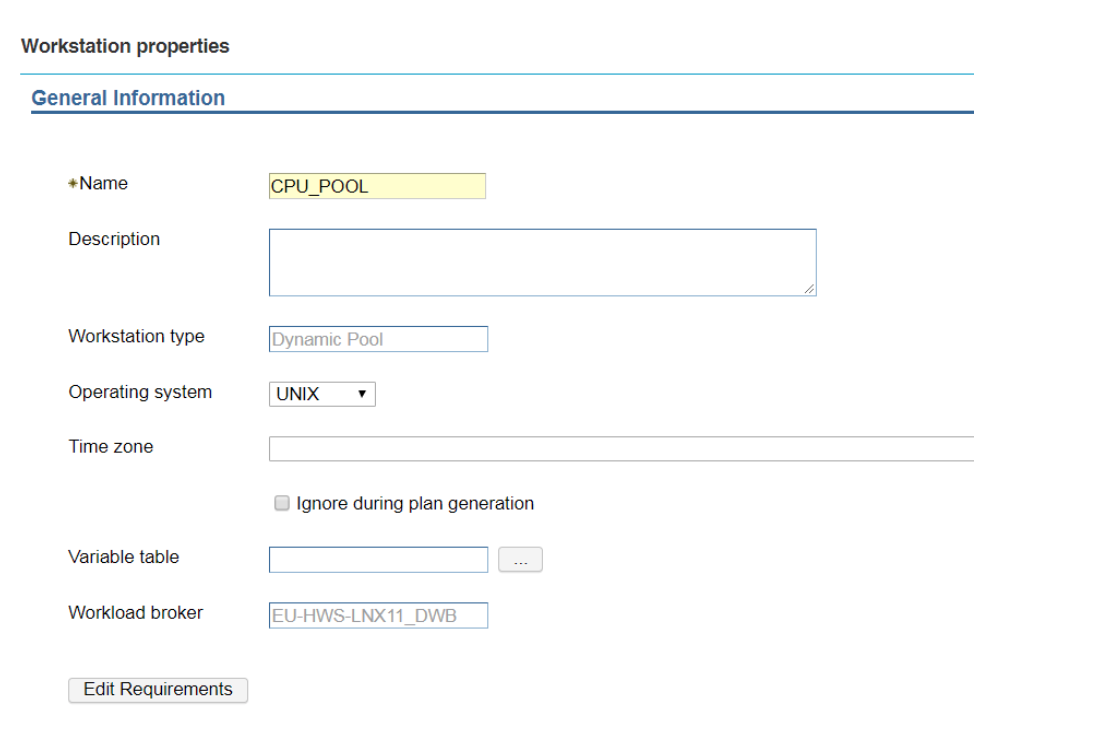 Using “Edit Requirements” it is possible to associate the logical resources to the new pool. 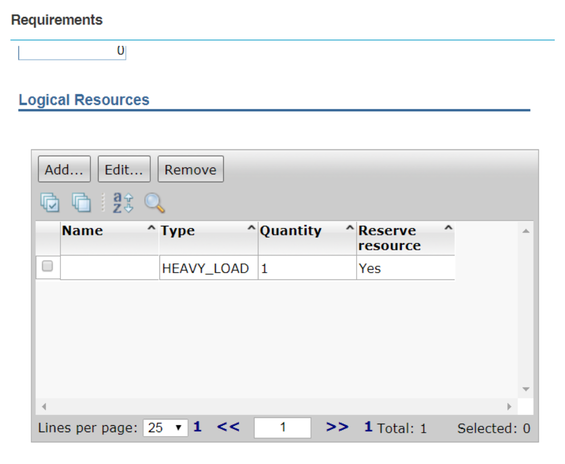 Adding the logical resource to the pool, it is necessary to associate the resources by type, not by name (so in this case we have to specify HEAVY_LOAD and not AGT1 or AGT2, the names of the logical resources), then specify the quantity to consume (1) and if the resource needs to be reserved (Yes). Finally it is necessary to set the optimization method to use: in this case it is based on the lowest utilization of the logical resources.  In this way, when the job CPU_POOL#HEAVYJOB_1 is submitted, it will be assigned to one of the workstations in the pool. Let’s assume it is assigned to AGT94, consuming the resource AGT2, type HEAVY_LOAD. The concurrent submission of the job CPU_POOL#HEAVY_JOB_2 won’t be send to AGT94 (if CPU_POOL#HEAVYJOB_1 is still running) since its resource AGT2 is still in use. The job will be executed on the workstation EU-HWS-LNX110_1, where the resource AGT1 will be consumed. Note that in this case another job submission, CPU_POOL#HEAVY_JOB_3, while HEAVY_JOB_1 and HEAVY_JOB_2 are still in EXEC status, will remain waiting for the availability of resources, so waiting for HEAVY_JOB_1 or HEAVY_JOB_2 to finish. For this reason, the suggestion is to avoid to define other jobs that could disturb the “critical” jobs on pool CPU_POOL. It is better to define another pool, even including the same workstations of CPU_POOL but without the resource type HEAVY_LOAD, for ordinary jobs. This allows, for example, jobs ORDINARY_POOL#LIGHT_JOB and CPU_POOL#HEAVY_JOB_3 to run simultaneously on the workstation EU-HWS-LNX110_1 (belonging to both the pools). If you have any feedback or want to know more about Dynamic Scheduling, contact Paolo Salerno: paolo.salerno@hcl.com.
3 Comments
2/20/2019 11:22:51 am
Actually, I don't have a deep understanding about this matter. Workload Automation is a very complicated topic ranging from basic information up to the biggest ones. Despite the difficulty, there is still in me wanting to learn the flow of Workload Automation. I can see a possibility of learning it and eventually benefiting from it. Hopefully, it will happen anytime soon, because I have the wiliness to make it possible right now. I need to invite my friends too to join this.
Zoltan Szabo
4/3/2020 07:14:52 am
Hi, 4/19/2020 02:28:07 pm
There are multiple workload automation tools on the market. Readers might find it helpful to look at reviews of different workload automation tools on IT Central Station to see which is best suited to their needs: https://www.itcentralstation.com/categories/workload-automation/tzd/c1099-sbc-55 Your comment will be posted after it is approved.
Leave a Reply. |
Archives
August 2023
Categories
All
|

 RSS Feed
RSS Feed