 Nowadays, the global marketplace requires systems that can react to fluctuating loads and unpredictable failures, with the end-level agreement (SLA) goal of being available 99.999% of the time. Mitigating the negative impacts of failures, disasters and outages cannot even be contemplated in today’s competitive world. A disaster recovery strategy is too error-prone and resource-consuming: businesses need to operate following an “always on” model. This requirement makes no exception for Workload Automation that manages your business critical batch and real-time workload in a downtime-free environment. Workload Automation provides the following high availability options to help you meet the SLA goal: - DWC Replica in Active/Active configuration - Master Replica in Active/Passive configuration With Workload Automation V9.5 Fix Pack 2, the high availability configuration offers a new Automatic Failover feature, without the need for additional third-party software. These options, coupled with support for zero downtime upgrade methods for agents and the entire workload environment, ensures continuous business operations and protection against data loss. Want to see how you can configure High Availability in a single domain network, with scalable and auto-recoverable masters? Read on to find out how to leverage the new Automatic Failover feature to reduce, to a minimum, the impact on workload scheduling, and more in general, on the responsiveness of the overall system when scenarios of unplanned outages of one or more master components occur. A simple Workload Automation configuration: master not in high availability In a configuration with a single master, with both dynamic and fault-tolerant agent (FTA) workstations defined on it (Figure 1), you might already be aware of the various ways components auto-recover from a failure, or how they continue to perform their job without an active master:
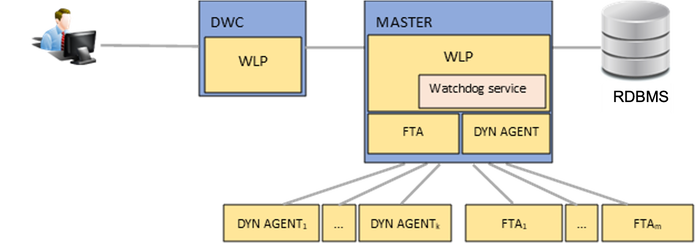 Figure 1. Single master configuration with dynamic and FTA agent workstations So, even with a simple configuration, you can still achieve a certain level of fault tolerance. And let’s not forget that you can already scale up/down your dynamic agents. For example, depending on how heavy the workload is on your workstations, you can choose to define a pool of dynamic agents and schedule your jobs on the defined pool so that jobs are balanced across the agents in the pool and are reassigned to available agents should an agent become unavailable (see this blog for more details on an elastic scale solution using Docker to configure a list of pools to which an agent can be associated). However, as you know, an environment that can only continue to orchestrate the jobs in the current plan at the FTA level, doesn’t quite cut it in the face of failure. You still rely on the availability of the master to schedule on dynamic agents, to extend your plan, and to solve dependencies between jobs running on different agents or domains. Workload Automation configuration: master in high availability The next incremental step toward high availability is to replicate the master in our network (Figure 2). Because the WA cluster configuration is active-passive, any replicated master instances will be backup replicas. 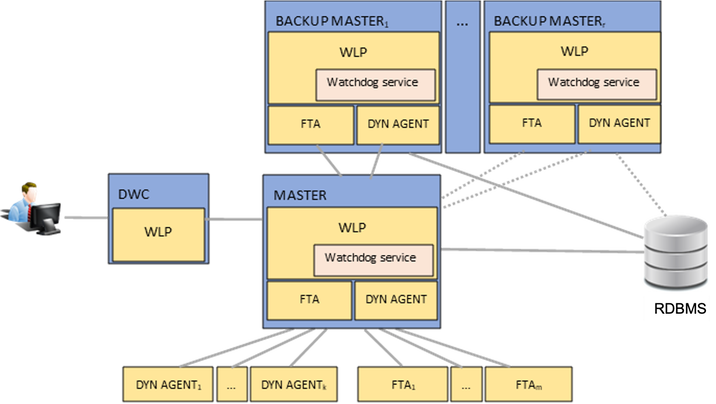 If an unplanned outage occurs, you can simply run the commands, conman switchmgrmasterdm;BKMi and conman switchevtproc BKM (to switch the master and event processor to a backup), from any of your backup masters (oh and by the way, since V9.5, you don’t need to manually stop/start the broker application anymore), and switch the workstations’ definition types FTA<->MASTER to make the switch permanent (the full procedure in this blog here). Moreover, to be able to schedule the FINAL job stream independently from what is the current master, you can define an XA (extended agent) workstation with $MASTER current host workstation and that is, the host of the current master). The FTAs and dynamic agents can link automatically to the newly selected master by reading the Symphony file and by checking the configured Resource Advisor URL list (the list of the master’s endpoints). With this, your workload resumes enabling business continuity. Ok, but this requires some kind of a monitoring system that would alert IT teams of failures and, after analyzing the issue, would run the switch manager procedure. Alternatively, high availability can be achieved automatically by using an external supervisor system suitably configured, such as TSAMP (IBM Tivoli System Automation for Multiplatforms). So you ask, how can you further minimize system unavailability? Keep reading. Master in high availability with automatic failover enabled Starting with Version 9.5 Fix Pack 2, you can leverage the new Automatic Failover feature: the first backup engine to automatically verify and detect if the active master is unavailable starts the long-term permanent switchmgr to [FM1] itself; Similarly, the same applies to the event processor. The backup event processor(s) automatically verifies and detects that the active event processor (that can be different from the current master workstation) is unavailable, and then starts the long-term switchevtproc to itself. And not only that, but the masters (active or passive) practice self-awareness: they can check the local FTA status and, if any of the processes go down, they are able to automatically start the recovery of the FTA. To better understand how the automatic failover feature works, let’s look at some details about the role each component plays to detect a failure or recover from it:
Nice, right? This feature is automatically enabled and the XA workstation hosted by the $MASTER hostname with FINAL and FINALPOSTREPORTS job streams in a UNIX environment is automatically created at installation time with a WA fresh installation. Otherwise , if you are coming from a product update or upgrade, after you have migrated your backups and your master, you can enable the feature via the optman command, optman chg enAutomaticFailover = yes and change the FINAL and FINALPOSTREPORTS job streams to move the job streams and all of the jobs from the master to the XA workstation. Let's suppose that you have multiple backup masters and you want to have greater control over which one of them should be considered first as the candidate master for the switch operation, well, for your convenience, you can use the following new optman options:
These are two separate lists of workstations, each list containing an ordered comma-separated list of workstations that serve as backups for the master and event processor, respectively. If a workstation is not included in the list, then it will never be considered as a backup. The switch is first attempted by the first workstation in the list and, if it fails, an attempt is made by the second in line, and so on. If no workstation is specified in this list, then all backup master domain managers in the domain are considered eligible backups. This gives you an extra level of control over your backups. For further granularity, you can choose to use only a subset of one list in the other list, or, choose to use two completely different lists. You might have a backup that can serve as the event manager backup, but you don’t want it to be considered as a potential master domain manager backup. Also, if the event manager fails, but the master domain manager is running fine, then only the event manager switches to a backup manager defined in the list of potential backups. Another example where these two distinct lists can be useful is if you have a dedicated environment for job orchestration and a different one for the event processor. You can continue to keep this separation of duties by enabling automatic failover and configuring the new optman options accordingly (Figure 3): 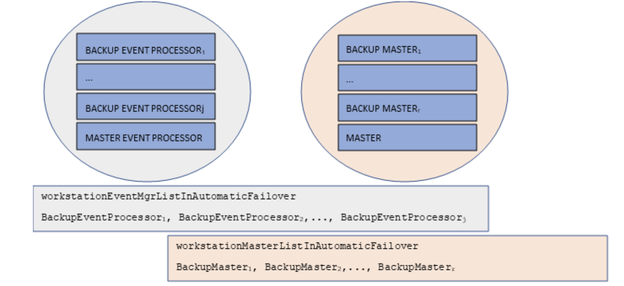 Figure 3 Separate backup lists for MDM and event processor If you have a Dynamic Workload Console (DWC) and/or other client application based on the exposed REST API of the master, you might be worried about how to replace the new master connection info when an automatic switch occurs. The best way you can do this is with a load balancer sitting in front of your masters and behind the DWC, and by specifying the public hostname of the load balancer as the endpoint of your engine connections in the DWC or in your client apps. In this way, you won’t have to know what the hostname of the current active master is to interact with Workload Automation features ( Figure 4). This becomes possible with another feature introduced in Fix Pack 2 that enables any backup master to satisfy any HTTP request, even in the event of a request that can be satisfied only by the active master (i.e. requests on the Workload Service Assurance) by proxying the request to/from the active master itself . 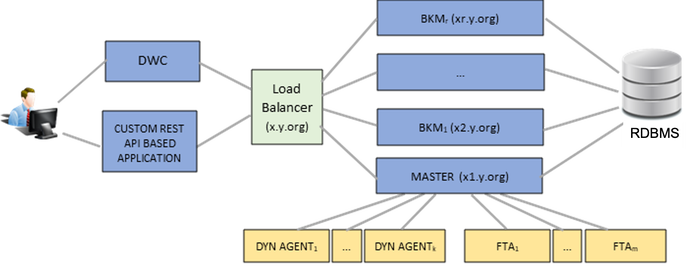 Figure 4 Load balancer placed behind the MDM and BKMs DWC, Master and RDBMS in high availability: WA in full high availability At this point, to have a fully high available WA environment, the only thing missing is configuring the RDBMS and DWC in high availability. If your RDBMS has the HADR feature and you have enabled it (a Db2 example here), you can configure the liberty server’s datasource.xml file of the master and backup components, adding the failover properties, whose key-value pairs depend on the specific RDBMS vendor. Db2’s datasource can be configured with this set of properties in the XML element named properties.db2.jcc: <properties.db2.jcc databaseName="TWS" user="…" password="…" serverName="MyMaster" portNumber="50000" clientRerouteAlternateServerName="MyBackup" clientRerouteAlternatePortNumber="50000" retryIntervalForClientReroute="3000" maxRetriesForClientReroute="100" /> For the DWC, instead, you just need to ensure that it is connected to an external DB (not the embedded one), replicate it, and link it to a load balancer that supports session affinity, to dispatch the request related to the same user session to the same DWC instance. In Figure 5, the load balancers are depicted as two distinct ones, the most general case possible, but you can also use the same component for balancing the request to the DWC and to the masters: 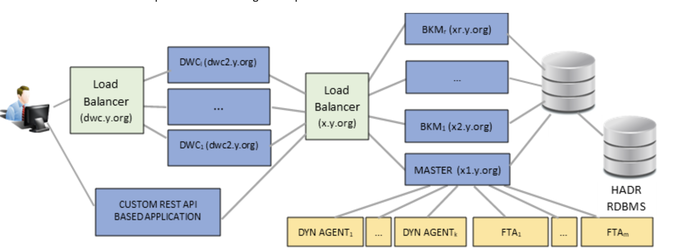 Figure 5 Full high availability WA environment At this point, congratulations, you have reached a full WA environment in high availability! Author's Bio
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
August 2023
Categories
All
|



 RSS Feed
RSS Feed