 In this blog, we are going to walk you through enabling session affinity for the Dynamic Workload Console (console) deployed in a Google Kubernetes Engine (GKE) cluster that uses an HTTP(S) load balancer network service that leverages an instance of Google Cloud SQL for SQL Server managed database. In a GKE cluster environment, a backend service defines how the HTTP(S) cloud load balancing network service distributes incoming traffic. By default, the method for distributing new connections uses a hash calculated based on five pieces of information:
You can modify the traffic distribution method for HTTP(S) traffic by specifying a session affinity option. 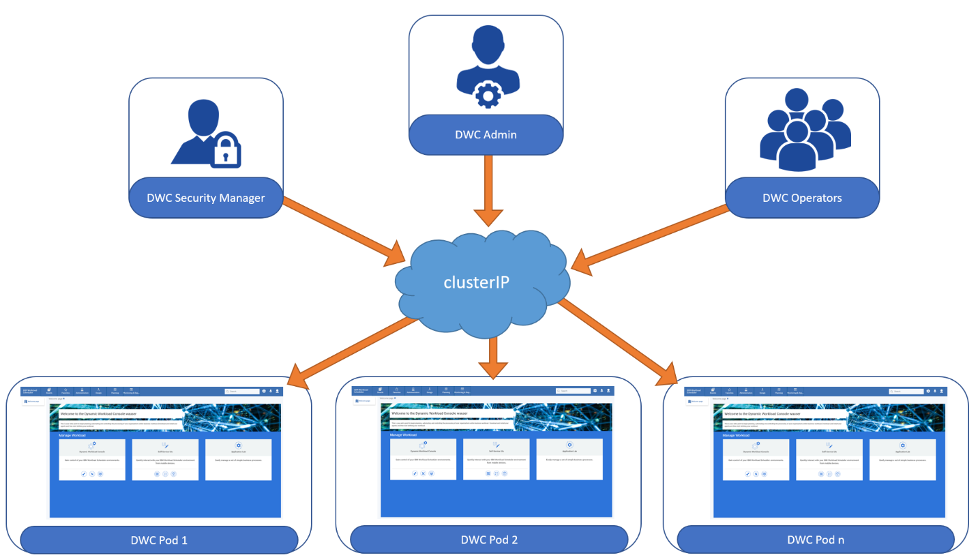 Let’s start by asking a couple of questions about the Workload Automation (WA) deployment in a GKE cluster regarding the console network. When hundreds of users are logged into the web console, how are inbound traffic requests handled? How is the inbound traffic from the console clients redirected to the multiple console instances installed as a pod in the cluster? As for the Kubernetes proxy models, the WA traffic bound for the service's IP:Port is proxied to an appropriate backend without the clients having any knowledge of Kubernetes, services, or pods. If you want to be sure that all connections from a particular WA console client always pass to the same WA console pod, you can set the session affinity based on the client IP addresses by exposing the Load Balancer Session Affinity service type in the configuration file of your WA deployment. Continue reading this blog to discover exactly how to do that! Configure the WA console with session affinity For more information about where you can download WA containers to install, or the related helm chart, see the appropriate readme file:
To deploy the Workload Automation console and enable session affinity, you simply expose the LoadBalancer_SessionAffinity service type. This can be done by editing the values.yaml file as follows.  NOTE: This type of service is only available for the console. With session affinity enabled, you can be sure that you are always connected to the same console pod, keeping your session always active. In this way, you can continue to automate your workload without interruption. Configure the WA console with Google Cloud SQL for SQL Server Embrace the power of Google cloud native services such as Google Cloud SQL. Workload Automation supports the installation of the server and console on Cloud SQL for SQL Server. To take advantage of the flexibility of the Google Cloud Database. Check this out! From the Google Cloud Platform Console, search for the “cloud sql” resource and create a new SQL Instance of the SQL Server. 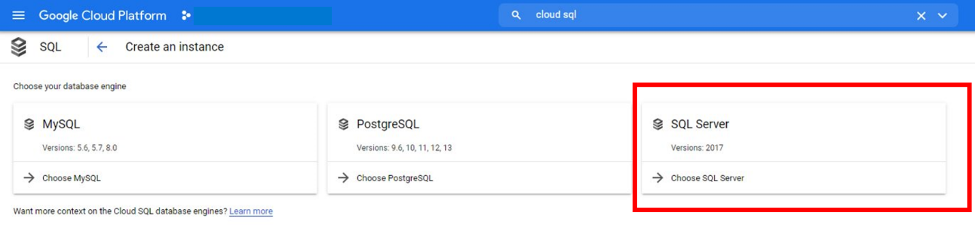 Once your database instance is up and running, you can customize the values.yaml file with the information of your new database. To install the Dynamic Workload Console on Cloud SQL, configure your deployment as follows: To also install the server component on Cloud SQL, configure your deployment as follows: 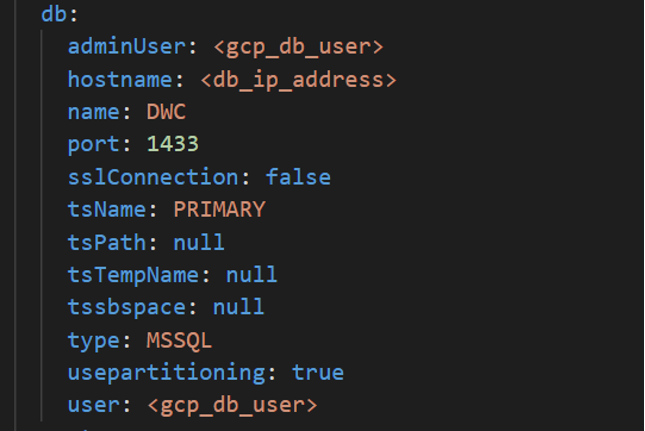 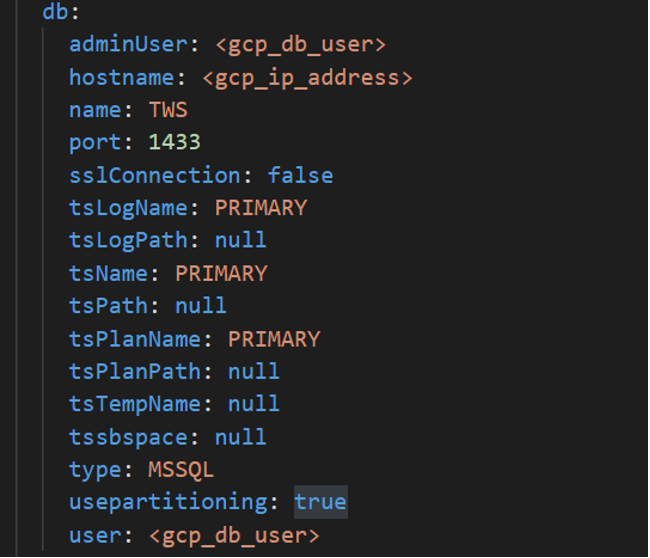 Configure the WA server with an internal or public load balancer If you need to manage traffic across multiple servers in your GCP cluster, you can opt for an internal or public load balancer.
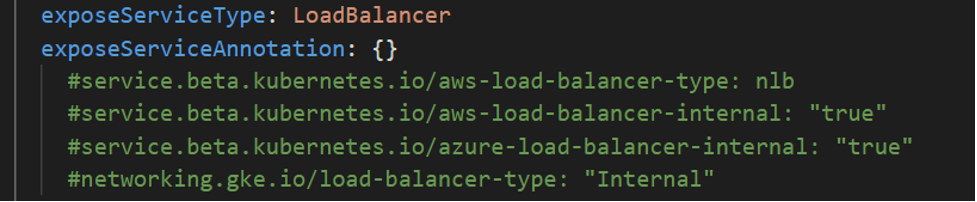
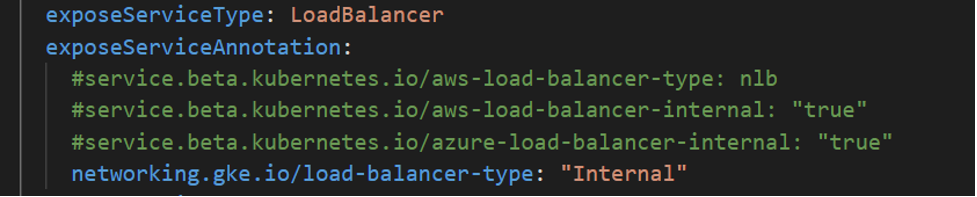 Deploy your Workload Automation configuration for the console and server After you have completed customizing the values in your values.yaml file , including the values explained earlier in this blog, you are ready to deploy your Workload Automation environment, including the console, on your GKE cluster. For more information about how to deploy, read the following README files:  We hope you enjoyed this article, and that you will take the time to try out a configuration of this kind. You won’t regret it. Send us your feedback and comments, they help us to provide you with useful content! Do not hesitate to reach out to us for any questions or doubts! Author's
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
July 2024
Categories
All
|






 RSS Feed
RSS Feed