 In this Blog ,we would look at how a team wanting to Integrate with Hadoop for running a Map Reduce Program could go about checking the pre-requisites from Hadoop Side and also go about then defining a Hadoop Map Reduce Job type to achieve this integration. Pre-Requisites: Assume we have a HWA Agent installed on the System where I have Hadoop NameNode setup and I have all the processes of Hadoop up and running on this Agent through start-all.sh or through start-dfs.sh and start-yarn.sh ,ofcourse same needs to verified on all Nodes of the Hadoop Cluster : [hadoop@RMMYCLDDL73611 ~]$ ps -ef | grep java | grep hadoop hadoop 18463 1 0 Mar16 ? 00:29:44 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06 -2.el8_5.x86_64/jre/bin/java -Dproc_datanode - Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS - Dyarn.log.dir=/home/hadoop/hadoop-3.3.1//logs - Dyarn.log.file=hadoop-hadoop-datanode-RMMYCLDDL73611.log - Dyarn.home.dir=/home/hadoop/hadoop-3.3.1/ - Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/home/hadoop/hadoop- 3.3.1//logs -Dhadoop.log.file=hadoop-hadoop-datanode- RMMYCLDDL73611.log -Dhadoop.home.dir=/home/hadoop/hadoop-3.3.1/ - Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA - Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.datanode.DataNode hadoop 18699 1 0 Mar16 ? 00:12:56 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06- 2.el8_5.x86_64/jre/bin/java -Dproc_secondarynamenode - Djava.net.preferIPv4Stack=true -Dhdfs.audit.logger=INFO,NullAppender - Dhadoop.security.logger=INFO,RFAS - Dyarn.log.dir=/home/hadoop/hadoop-3.3.1//logs - Dyarn.log.file=hadoop-hadoop-secondarynamenode-RMMYCLDDL73611.log - Dyarn.home.dir=/home/hadoop/hadoop-3.3.1/ - Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/home/hadoop/hadoop- 3.3.1//logs -Dhadoop.log.file=hadoop-hadoop-secondarynamenode- RMMYCLDDL73611.log -Dhadoop.home.dir=/home/hadoop/hadoop-3.3.1/ - Dhadoop.id.str=hadoo -Dhadoop.root.logger=INFO,RFA - Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode hadoop 18990 1 0 Mar16 ? 01:15:25 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06- 2.el8_5.x86_64/jre/bin/java -Dproc_resourcemanager - Djava.net.preferIPv4Stack=true -Dservice.libdir=/home/hadoop/hadoop- 3.3.1//share/hadoop/yarn,/home/hadoop/hadoop- 3.3.1//share/hadoop/yarn/lib,/home/hadoop/hadoop- 3.3.1//share/hadoop/hdfs,/home/hadoop/hadoop- 3.3.1//share/hadoop/hdfs/lib,/home/hadoop/hadoop- 3.3.1//share/hadoop/common,/home/hadoop/hadoop- 3.3.1//share/hadoop/common/lib -Dyarn.log.dir=/home/hadoop/hadoop- 3.3.1//logs -Dyarn.log.file=hadoop-hadoop-resourcemanager- RMMYCLDDL73611.log -Dyarn.home.dir=/home/hadoop/hadoop-3.3.1/ - Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/home/hadoop/hadoop- 3.3.1//logs -Dhadoop.log.file=hadoop-hadoop-resourcemanager- RMMYCLDDL73611.log -Dhadoop.home.dir=/home/hadoop/hadoop-3.3.1/ - Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA - Dhadoop.policy.file=hadoop-policy.xml - Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.yarn.server.resourcemanager.ResourceManager hadoop 19175 1 0 Mar16 ? 00:45:04 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06- 2.el8_5.x86_64/jre/bin/java -Dproc_nodemanager - Djava.net.preferIPv4Stack=true -Dyarn.log.dir=/home/hadoop/hadoop- 3.3.1//logs -Dyarn.log.file=hadoop-hadoop-nodemanager- RMMYCLDDL73611.log -Dyarn.home.dir=/home/hadoop/hadoop-3.3.1/ - Dyarn.root.logger=INFO,console -Dhadoop.log.dir=/home/hadoop/hadoop- 3.3.1//logs -Dhadoop.log.file=hadoop-hadoop-nodemanager- RMMYCLDDL73611.log -Dhadoop.home.dir=/home/hadoop/hadoop-3.3.1/ - Dhadoop.id.str=hadoop -Dhadoop.root.logger=INFO,RFA - Dhadoop.policy.file=hadoop-policy.xml - Dhadoop.security.logger=INFO,NullAppender org.apache.hadoop.yarn.server.nodemanager.NodeManager hadoop 2454420 2438238 0 13:34 pts/0 00:00:00 grep -- color=auto java Important to verify that the Hadoop Version can be tested and returns proper output as expected: [hadoop@RMMYCLDDL73611 sbin]$ hadoop version Hadoop 3.3.1 Source code repository https://github.com/apache/hadoop.git -r a3b9c37a397ad4188041dd80621bdeefc46885f2 Compiled by ubuntu on 2021-06-15T05:13Z Compiled with protoc 3.7.1 From source with checksum 88a4ddb2299aca054416d6b7f81ca55 This command was run using /home/hadoop/hadoop- 3.3.1/share/hadoop/common/hadoop-common-3.3.1.jar If all is good and working well , then the JAVA_HOME and HADOOP_HOME environment variables are also expected to be working fine : [hadoop@RMMYCLDDL73611 sbin]$ echo $JAVA_HOME /home/hadoop/TWS/JavaExt/jre [hadoop@RMMYCLDDL73611 sbin]$ echo $HADOOP_HOME /home/hadoop/hadoop-3.3.1/ If all of this is verified and good , we can go about testing our Hadoop Map Reduce Code through Hadoop CLI first : In the below example I have a simple Hadoop Map Reduce Program written where the input file is being verified in the input directory of Hadoop Filesystem : [hadoop@RMMYCLDDL73611 ~]$ $HADOOP_HOME/bin/hadoop fs -ls input_dir/ Found 1 items -rw-r--r-- 1 hadoop hadoop 344 2022-04-01 13:16 input_dir/sample.txt Next , I go about verifying if the Code is executing well through Hadoop CLI : [hadoop@RMMYCLDDL73611 ~]$ $HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir 2022-04-01 13:16:48,367 INFO impl.MetricsConfig: Loaded properties from hadoop- metrics2.properties 2022-04-01 13:17:08,996 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 2022-04-01 13:17:08,996 INFO impl.MetricsSystemImpl: JobTracker metrics system started 2022-04-01 13:17:09,083 WARN impl.MetricsSystemImpl: JobTracker metrics system already initialized! 2022-04-01 13:17:09,201 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2022-04-01 13:17:09,284 INFO mapred.FileInputFormat: Total input files to process : 1 2022-04-01 13:17:09,342 INFO mapreduce.JobSubmitter: number of splits:1 2022-04-01 13:17:10,017 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local1122970586_0001 2022-04-01 13:17:10,017 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2022-04-01 13:17:10,250 INFO mapreduce.Job: The url to track the job: https://localhost:8080/ 2022-04-01 13:17:10,256 INFO mapreduce.Job: Running job: job_local1122970586_0001 2022-04-01 13:17:10,256 INFO mapred.LocalJobRunner: OutputCommitter set in config null 2022-04-01 13:17:10,261 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapred.FileOutputCommitter 2022-04-01 13:17:10,265 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2 2022-04-01 13:17:10,265 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 2022-04-01 13:17:10,310 INFO mapred.LocalJobRunner: Waiting for map tasks 2022-04-01 13:17:10,323 INFO mapred.LocalJobRunner: Starting task: attempt_local1122970586_0001_m_000000_0 2022-04-01 13:17:10,342 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 2 2022-04-01 13:17:10,343 INFO output.FileOutputCommitter: FileOutputCommitter skip cleanup _temporary folders under output directory:false, ignore cleanup failures: false 2022-04-01 13:17:10,354 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ] 2022-04-01 13:17:10,360 INFO mapred.MapTask: Processing split: file:/home/hadoop/input_dir/sample.txt:0+344 2022-04-01 13:17:10,401 INFO mapred.MapTask: numReduceTasks: 1 2022-04-01 13:17:10,499 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584) 2022-04-01 13:17:10,499 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100 2022-04-01 13:17:10,499 INFO mapred.MapTask: soft limit at 83886080 2022-04-01 13:17:10,499 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600 2022-04-01 13:17:10,499 INFO mapred.MapTask: kvstart = 26214396; length = 6553600 2022-04-01 13:17:10,503 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer 2022-04-01 13:17:10,507 INFO mapred.LocalJobRunner: map task executor complete. Now we can proceed and start defining this job in HWA Side : Inorder to define the job in HWA , we would need the following details :
Specify the Home Directory of the Hadoop Filesystem , in this case it is /home/hadoop/hadoop-3.3.1 which is the Home path that includes bin directory (two steps behind hadoop binary):  Select the hadoop Jar file comprising of all Classes of the packaged application from the specific location : in this case /home/Hadoop/units.jar :  Also , Enter the Main Class to be executed , in this case it is hadoop.ProcessUnits : All Arguments to be passed to Hadoop Map Reduce Program as input such input_dir where all input files for the Hadoop Map Reduce program are present and output_dir for the Output is mentioned under Arguments section : 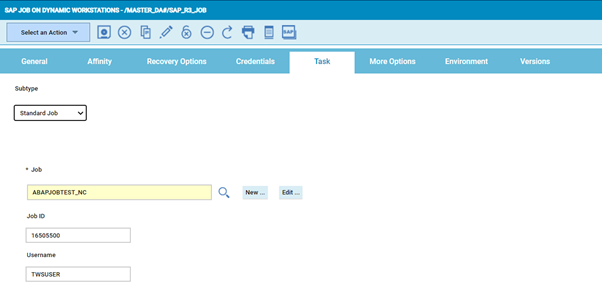 Once the job is Saved with all the above parameters , we are ready to test the Hadoop map Reduce program , so one can go ahead and submit the job through HWA , one could access the joblog as follows : %sj DARMMYCLDDL#555488804 std sin =============================================================== = JOB : DARMMYCLDDL#JOBS[(0430 01/12/22),(JOBS)].HADOOP_TEST = TASK : <?xml version=”1.0″ encoding=”UTF-8″?> <jsdl:jobDefinition xmlns:jsdl=”https://www.ibm.com/xmlns/prod/scheduling/1.0/jsdl” xmlns:jsdlhadoopmapreduce=”https://www.ibm.com/xmlns/prod/scheduling/ 1.0/jsdlhadoopmapreduce” name=”HADOOPMAPREDUCE”> <jsdl:variables> <jsdl:stringVariable name=”tws.jobstream.name”>JOBS</jsdl:stringVariable> <jsdl:stringVariable name=”tws.jobstream.id”>JOBS</jsdl:stringVariable> <jsdl:stringVariable name=”tws.job.name”>HADOOP_TEST</jsdl:stringVariable> <jsdl:stringVariable name=”tws.job.workstation”>DARMMYCLDDL</jsdl:stringVariable> <jsdl:stringVariable name=”tws.job.iawstz”>202201120430</jsdl:stringVariable> <jsdl:stringVariable name=”tws.job.promoted”>NO</jsdl:stringVariable> <jsdl:stringVariable name=”tws.job.resourcesForPromoted”>10</jsdl:stringVariable> <jsdl:stringVariable name=”tws.job.num”>555488804</jsdl:stringVariable> </jsdl:variables> <jsdl:application name=”hadoopmapreduce”> <jsdlhadoopmapreduce:hadoopmapreduce> <jsdlhadoopmapreduce:HadoopMapReduceParameters> <jsdlhadoopmapreduce:hadoop> <jsdlhadoopmapreduce:hadoopDir>/home/hadoop/hadoop-3.3.1</jsdlhadoopmapreduce:hadoopDir> <jsdlhadoopmapreduce:jarName>/home/hadoop/units.jar</jsdlhadoopmapreduce:jarName> <jsdlhadoopmapreduce:className>hadoop.ProcessUnits</jsdlhadoopmapreduce:className> <jsdlhadoopmapreduce:arguments>input_dir output_dir</jsdlhadoopmapreduce:arguments> </jsdlhadoopmapreduce:hadoop> </jsdlhadoopmapreduce:HadoopMapReduceParameters> </jsdlhadoopmapreduce:hadoopmapreduce> </jsdl:application> <jsdl:resources> <jsdl:orderedCandidatedWorkstations> <jsdl:workstation>CA23B7F6988C11EC9975777E02EE46EC</jsdl:workstation> </jsdl:orderedCandidatedWorkstations> </jsdl:resources> </jsdl:jobDefinition> = TWSRCMAP : = AGENT : DARMMYCLDDL = Job Number: 555488804 = Mon 02/28/2022 18:04:31 IST =============================================================== – Hadoop Map Reduce 2022-02-28 18:04:32,788 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032 2022-02-28 18:04:32,989 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at /0.0.0.0:8032 2022-02-28 18:04:33,160 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 2022-02-28 18:04:33,175 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1645770694021_0006 2022-02-28 18:04:33,398 INFO mapred.FileInputFormat: Total input files to process : 0 2022-02-28 18:04:33,456 INFO mapreduce.JobSubmitter: number of splits:0 2022-02-28 18:04:33,917 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1645770694021_0006 2022-02-28 18:04:33,917 INFO mapreduce.JobSubmitter: Executing with tokens: [] 2022-02-28 18:04:34,108 INFO conf.Configuration: resource-types.xml not found 2022-02-28 18:04:34,109 INFO resource.ResourceUtils: Unable to find ‘resource-types.xml’. 2022-02-28 18:04:34,172 INFO impl.YarnClientImpl: Submitted application application_1645770694021_0006 2022-02-28 18:04:34,211 INFO mapreduce.Job: The url to track the job: https://RMMYCLDDL73611.nonprod.hclpnp.com:8088/proxy/application_1645770694021_0006/ 2022-02-28 18:04:34,212 INFO mapreduce.Job: Running job: job_1645770694021_0006 2022-02-28 18:04:36,227 INFO mapreduce.Job: Job job_1645770694021_0006 running in uber mode : false 2022-02-28 18:04:36,228 INFO mapreduce.Job: map 0% reduce 0% As you can see from above joblog this shows the JobID of the Hadoop Mapreduce job within Hadoop UI. The URL on Hadoop Side can also be used to track the job as seen. Authors Bio
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
July 2024
Categories
All
|


 RSS Feed
RSS Feed