 Let's start understanding Google BigQuery, and then go forward to discovering the GCP BigQuery plug-in and the benefits of using it. Google BigQuery is a serverless data warehousing platform where you can query and process vast amounts of data. The best part about it is, that one can run multiple queries in a matter of seconds, even if the datasets are relatively large in size. It is a Platform-as-a-Service (Paas) that supports querying using ANSI SQL. It also has built-in machine learning capabilities. Thus, to empower your Workload Automation environment, download the Google BigQuery plug-in available on Automation Hub. After downloading it, log in to the Dynamic Workload Console and go to the Workload Designer. Create a new job and select “Google BigQuery” in the Cloud section. 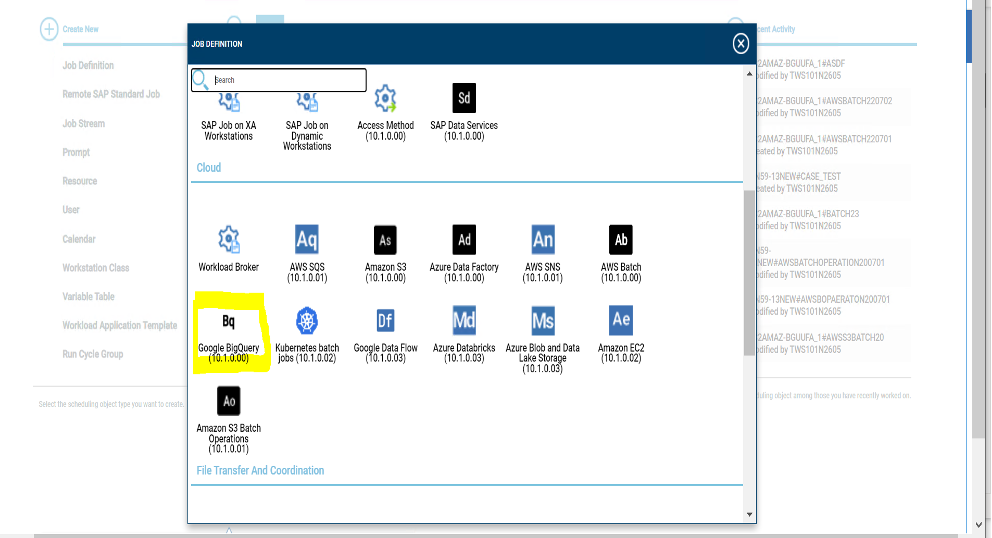 Figure 1: Job Definition page Connection First, establish a connection to the Google Cloud server. In the Connection tab, you can choose between two options to connect to Google Cloud: 1. GCP Default Credentials: you can choose this option if the VM already resides inside the GCP environment and there is no need to provide credentials explicitly. 2. GCP Server Credentials: you can choose this option to manually provide the GCS account and the project ID (a unique name associated with each project). Then, you can test the connection to Google Cloud by clicking on Test Connection. 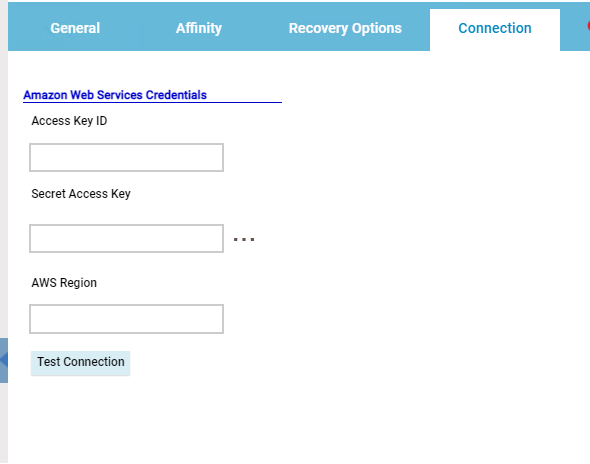 Figure 2: Connection page 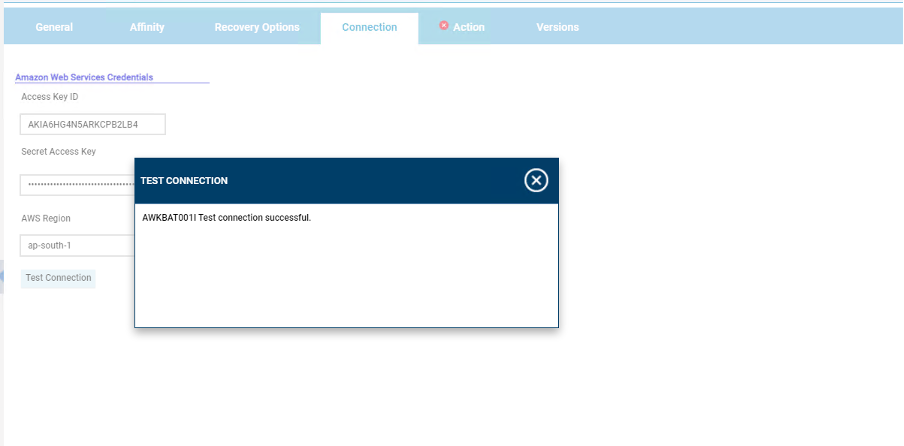 Figure 3: Connection page> Test Connection Action After having successfully tested the connection, you can go to the Action tab and specify the bucket name and the operation you want to perform: · Job Name: specify the name of the job. It must be unique among running jobs. · Region: choose a BigQuery regional endpoint to deploy worker instances and store job metadata. (For example, US, us east-1, etc.) · Standard SQL: choose it as the primary method to analyse data in BigQuery. It scans one or more tables or expressions and returns the computed result rows. (For example, Select * From ‘TABLE NAME’ Limit 1000)
For example: “CALL `bigquerysandbox-342206.emp.my_proc`();” The following statement calls the my_proc stored procedure. 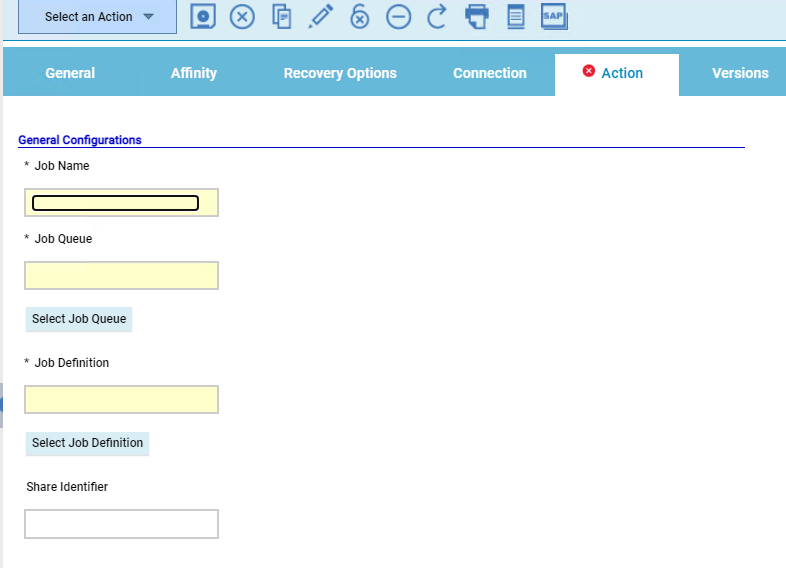 Figure 4: Action page
Choose it to load the data from a set of one or more files into a single database table. The file should be like JSON, CSV, AVRO, etc. Specify a name for the data set, a name for the table, and the source path of the Google storage (For example, “gs://cloud-samples-data/bigquery/us-states/us-states.csv”). 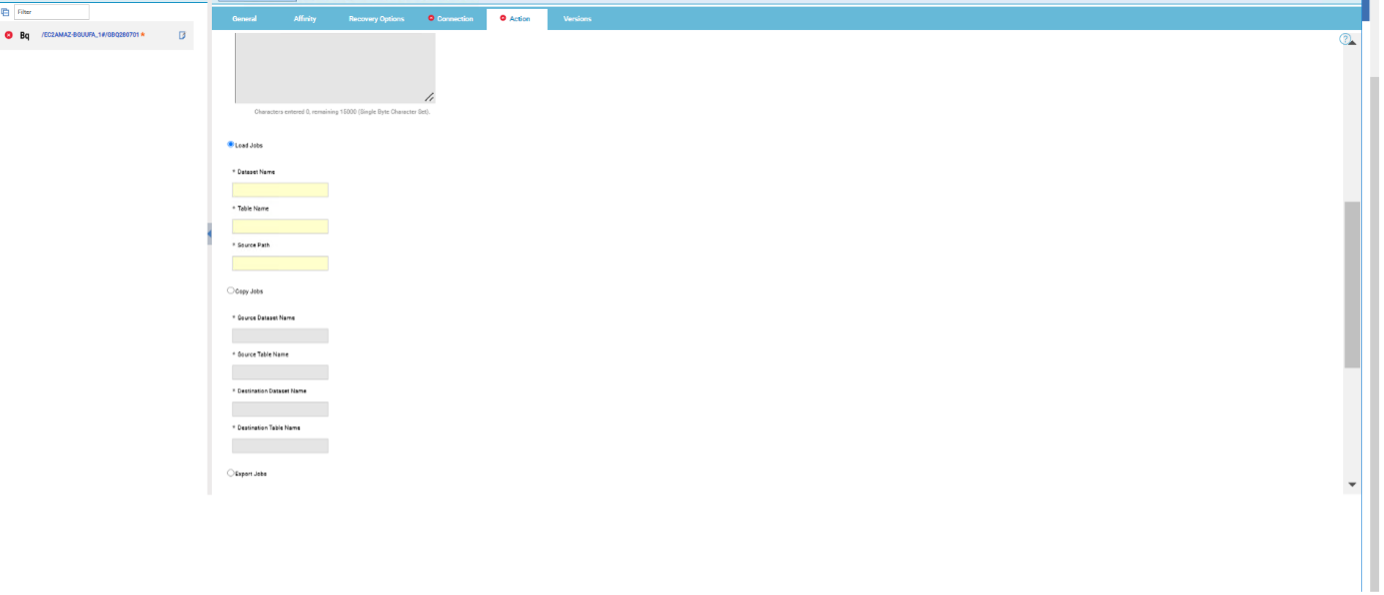 Figure 5: Action page> Load Jobs
Choose it to copy a dataset within a region or from one region to another, without having to extract, move, and reload data into BigQuery. First, you have to create a destination data set and a table where to transfer data, otherwise the plug-in creates them automatically. Then, you can fill out the fields providing the data set name, the source table name, the destination data set name, and the destination table name. 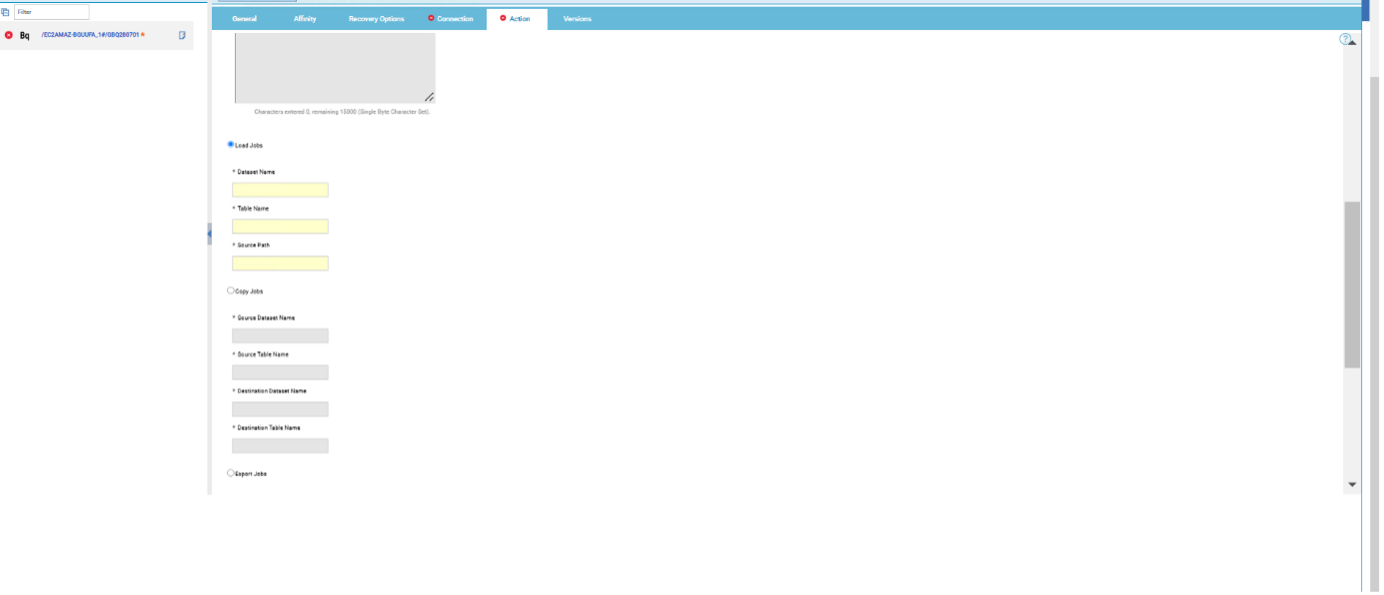 Figure 6: Action page> Copy Jobs
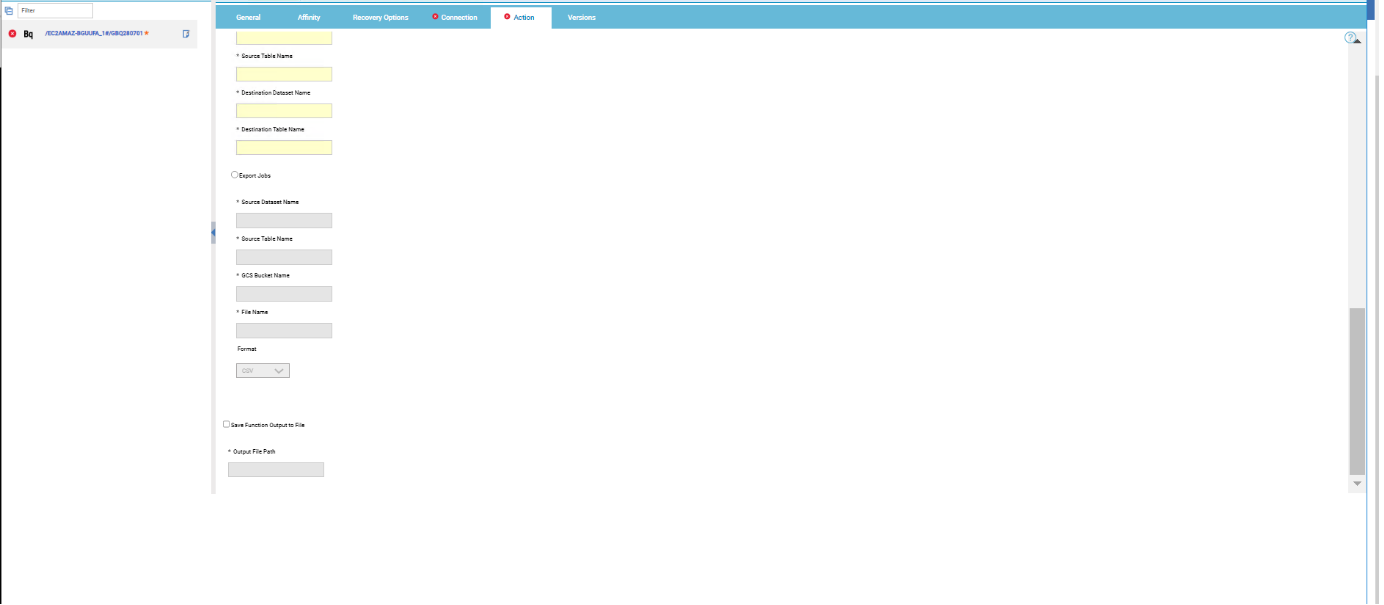 Figure 7: Action page> Export Jobs Then, enable Save Function Output to File and specify the output file path. 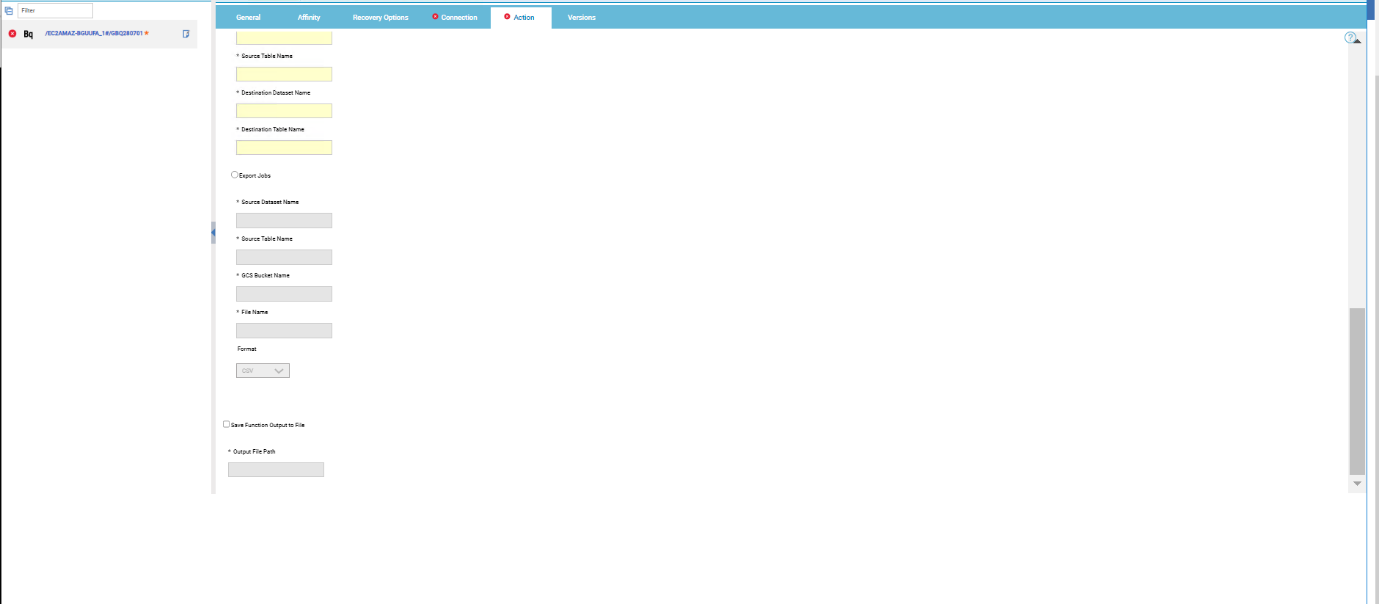 Figure 8: Action page Contd. Submitting your job Now, it is time to submit the job in the current plan. Add the job to the job stream that automates your business process flow. Select the action menu in the top-left corner of the job definition panel and click Submit Job into Current Plan. A confirmation message is displayed, and you can switch to the Monitoring view to see what is going on. 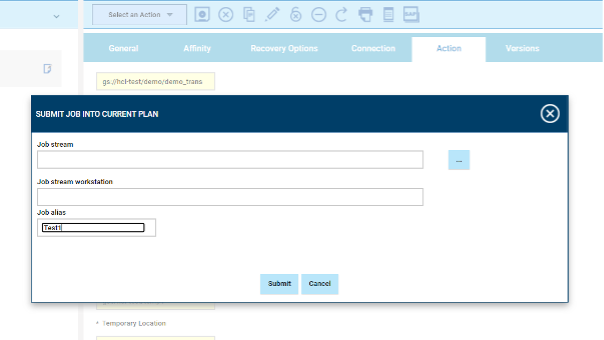 Figure 9: Submitting job Monitor Page:  Figure 10: Monitor Page Job Logs: 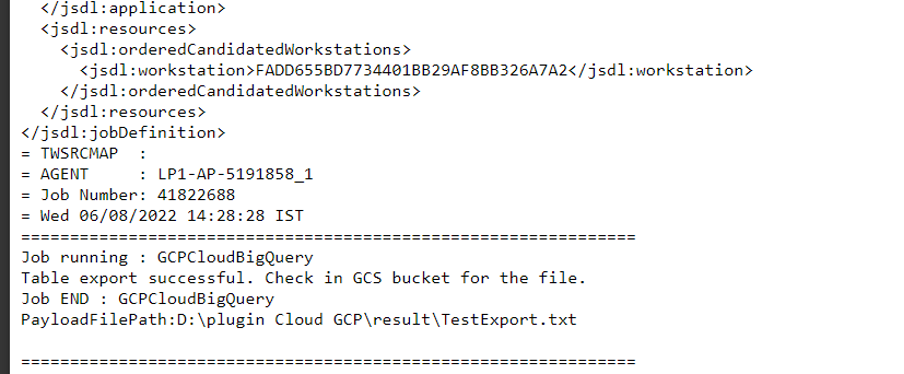 Figure 11: Job log Google BigQuery plug-in is easy and quick to install. Thanks to it you can orchestrate your cloud and big data automation processes and analyze a huge amount of data in a short time. So, then, what are you waiting to start using it? Download it now! Author's Bio
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
July 2024
Categories
All
|


 RSS Feed
RSS Feed