 Recently versions of Workload Automation product are capable of seamless integrating with observability products such as Dynatrace, Instana, Datadog, Splunk and others. This is useful specially for companies that has a large operations teams which are already monitoring applications on those observability solutions. Having the job / scheduling metrics, logs and events and co-relating them with actual application performance data, makes easy to uncover bottlenecks, identify potential SLAs breaches as well as making easy for the operator or SRE to identify jobs running/abending on the environment. In this blog post I will describe one of the pillars of observability from a Workload Automation point of view. HWA / IWA has exposed it’s metrics for the main components, the back-end (Master Domain Manager) which reports metrics around job execution as well as the health of it’s application server (Websphere liberty). As well as the front-end web user interface (Dynamic workload console – DWC). Those metrics are exposed in openmetrics format, which is a vendor neutral format widely adopted by the community, it originated from the Prometheus project and it’s been the standard way to report metrics for cloud native applications. For IBM / HWA to start reporting metrics we should first enable to openmetrics endpoint on all Websphere components (MDM / BKMDM / DWC). The process is well documented here. Once performed, the endpoints will be available on the HTTP/HTTPS ports: https://MDMIP:31116/metrics and https://DWCIP:9443/metrics When accessing the links we should see the openmetrics format data:
If the endpoints properly reporting the metrics we now move into sending the data to observability products. In our case we will leverage Prometheus as monitoring solution, we will set up Prometheus to scrape the HWA/IWA openmetrics endpoints so it’s ingested by it and once in there we are able to setup alerts or dashboards. Bellow is a Prometheus configuration example (/etc/prometheus/prometheus.yml) to scrape IWA/HWA’s openmetrics endpoints. Note the scrape_interval of 1 minute as well as we are disabling tls verification. In bellow example the MDM https port is 31116 and DWC’s is 443 (the default is 9443).
After recycling Prometheus, I can see the targets available on Prometheus’s UI. 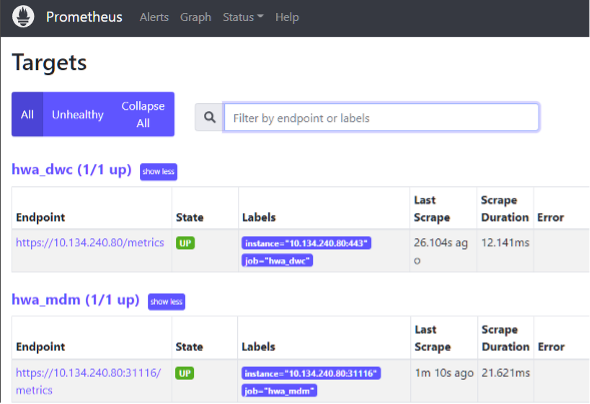 Figure 1 Prometheus targets With the data been received on Prometheus I am also able to search it by running promql queries as well as visualizing graphics.  Figure 2 Prometheus metrics Below picture shows a promql query to list jobs in error by workstation.  Figure 3 Prometheus error jobs by workstation By validating the metrics are being reporting properly on prometheus we can now leverage Grafana to display and build dashboards or/and leverage alertmanager to be alerted in case of issues. Regarding to Grafana, we can now leverage the Grafana dashboard available on yourautomationhub.io. The dashboard was built for Grafana with relevant data for scheduling environments. To use it on Grafana, first we need to define the prometheus datasource, according to below picture.  Figure 4 Grafana's Prometheus datasource Them all it takes is to import the HWA / IWA dashboard from Grafana’s import section. Type the id 14692 and it should load the dashboard automatically. Select the folder and the prometheus datasource name we did set up on the previous step and click import.  Figure 5 Import dashboard on grafana Once imported we can see all the metrics that is collected by prometheus on grafana’s dashboard:  Author's Bio
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
July 2024
Categories
All
|


 RSS Feed
RSS Feed