 A year ago, we published Workload Scheduler V9.4.0.0 Performance Report to document how Workload Automation Performance Team have a constant focus on performance, scalability and reliability of the product, even if the systematic introduction of new product functional capabilities, release after release, makes this sustaining performance levels a constant challenge. The results published on that Performance Report were related to a product installation based on IBM Power7 + AIX 7.1 infrastructure. In the last year, the increasingly widespread of VMWare-Linux adoption required specific performance benchmark to be run on this different reference architecture with the primary goal to consolidate the previous performance indicators detected with Power7-AIX environments. Furthermore, the continuous customer interaction contributed to better specialize the performance workload being able to provide best practices in many real customer business scenarios. The main objective of this article is to provide a brief description of the most important results obtained during this latest Workload Scheduler Performance assessment and to share the list of best practices identified to optimize Workload Scheduler product to run high workloads. Confirmation of previous throughput also in VM Linux environment From a scheduling workload perspective, the performance test executed for Workload Scheduler V9.4.0.3 in a test environment based on the VMWare ESX - Linux x86 platform confirmed the previous results:
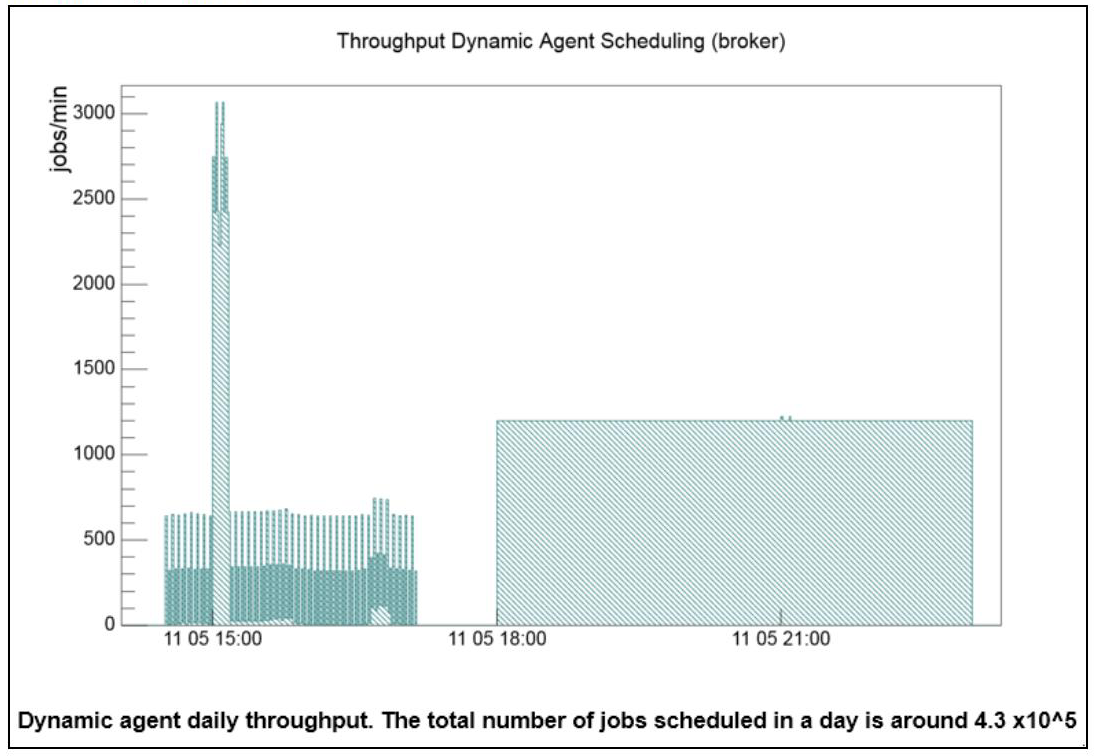
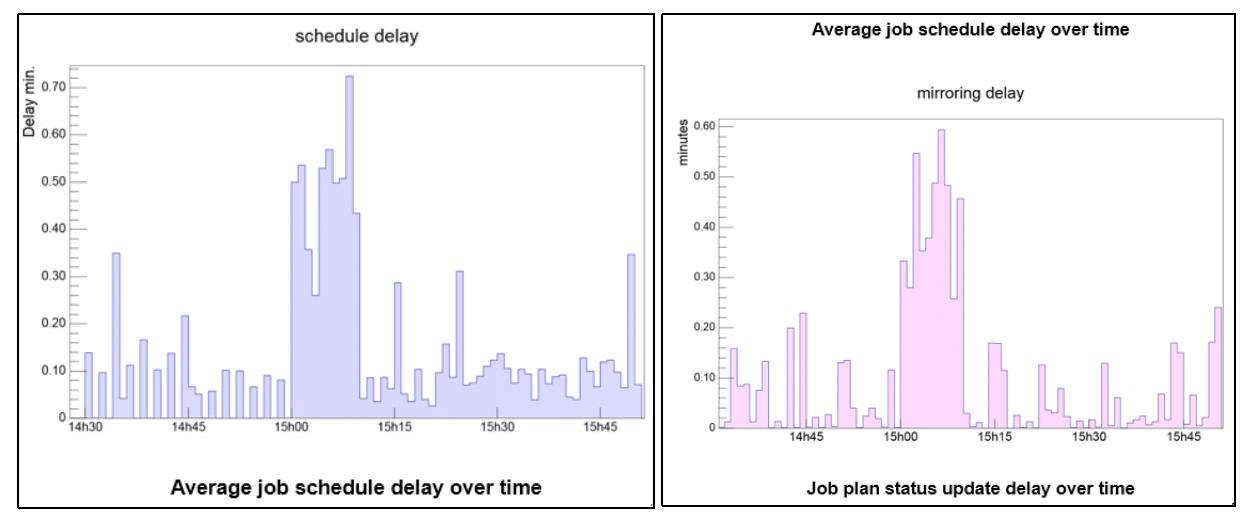 This behavior was validated in two different production-like environments (one with IBM DB2 and the second with Oracle database). Best Practices Workload Scheduler software offers many features to perform at best its own objective: orchestrate scheduling flow activities. The principal way to schedule is to have job streams included in the plan, by associating it to a run cycle, during the plan generation activity. In addition, the schedule of jobs and job streams could occur dynamically while the plan is running, using, for example, event rules, conman command, start conditions, and file dependencies. Even if the latter give a higher level of versatility to accomplish different business scenarios, there are some recommendations that must be considered before planning to adopt them to orchestrate the scheduler completely in case of a heavy workload. Scheduling using event rules It is possible to have event rules that trigger actions like job and job stream submission. These rules could detect, for example, a job status change or file creation events. In all of these cases, the events are sent to the event processor queue (cache.dat). In the case of a status change, the consumer is the batchman process, while in the case of remote file monitoring, the agent itself communicates with the event processor. In all of these cases, the final submission throughput strictly depends on event processor throughput capability. The event processor is a single thread process and its processing capacity is proportional to the core speed and the I/O capabilities of the system on which it runs. For this reason, it cannot scale horizontally. The benchmark was based on 6000 file creation rules, defined for 4 dynamic agents with more than 1.2x10^5 files created in one hour. The detected throughput of event processor was of about 400 events consumed per minute. 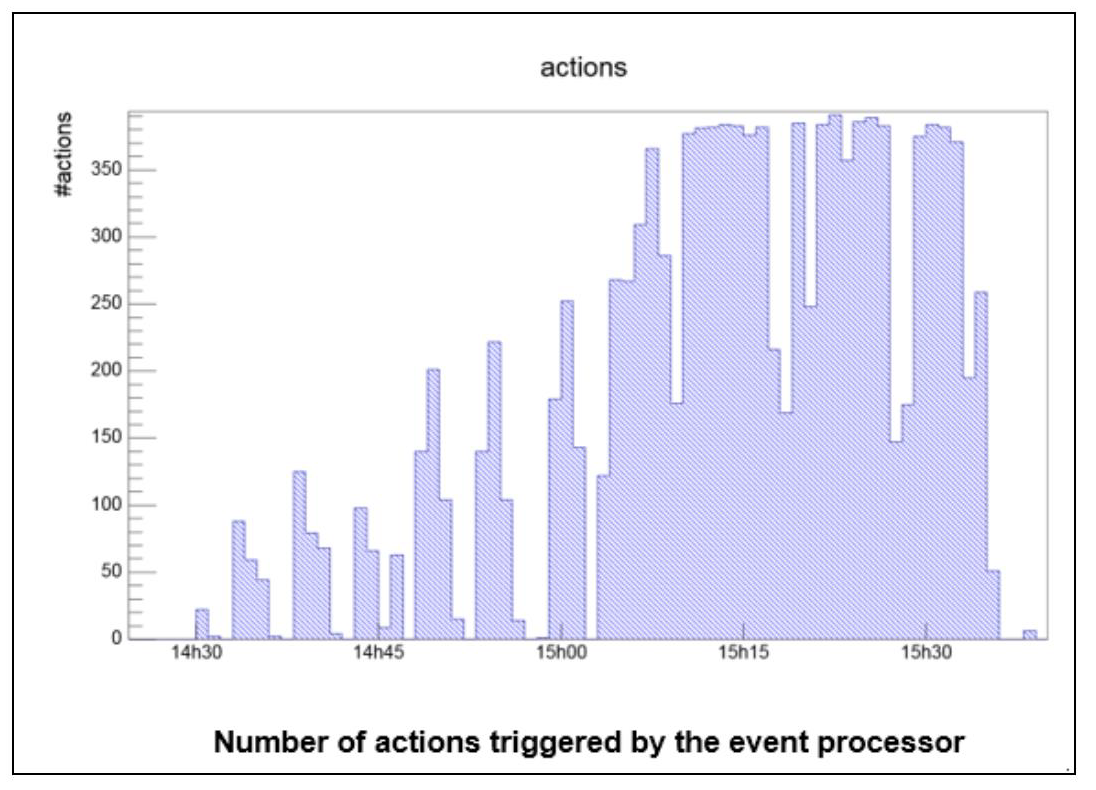 Scheduling using file dependencies Workload Scheduler allows the release of dependencies to perform scheduling. These releases could depend on several objects (jobs, job streams, resources). File dependency is often a useful feature to implement many business workflows that must be triggered by a file creation. This feature has a different impact on the performance if used with a dynamic agent. In case of a dynamic agent, the entire mechanism is driven by the dynamic domain manager that is in charge of the continuous check on the file existence status. The polling period is driven by the localopts property present on the Dynamic Domain Manager: bm check file = 300 (300 seconds is the default). It defines the frequency with which the dynamic agent is contacted by server about file status. The server workload throughput is ruled by three parameters: 1. Polling period 2. Number of file dependencies 3. Network connection between agents and server In the test environment used for Performance validation (with around network latency 0.1 ms), the file check throughput was evaluated to be around 44 seconds to check 1000 files. It is suggested to keep the ratio (number of file dependencies)/(bm check file) less than 0.7. Scheduling using conman sbs The ”conman sbs” (or equivalent RESTful calls) command adds a job stream to the plan on the fly. If the network of the added job stream is significantly complex, both in terms of dependencies and cardinality, it could cause a general delay in the plan update mechanism. In this scenario, due to scheduling coherence, all the initial updates pass through the main thread queue (mirrobox.msg) missing the benefit of multithreading. It is extremely difficult to identify the complexity of the network that would cause this kind of queueing, in any case, the order of magnitude is of several hundreds of jobs in the job streams and internal and/or external dependencies. In this case, the suggestion is to avoid to use dynamic scheduling submission feature triggered by ”conman sbs” (or equivalent RESTful calls) command. Browse Workload Scheduler Version 9.4 Fix Pack 3 Performance Report to learn more about Workload Scheduler V9.4.0.3 scalability and performance improvements, best practices, tunings and settings. If you want to talk more about performance/scalability and Workload Scheduler, leave us a comment below. We would be happy to discuss.
0 Comments
Your comment will be posted after it is approved.
Leave a Reply. |
Archives
July 2024
Categories
All
|


 RSS Feed
RSS Feed